Noble’s infrastructure for college data

Over the years, Noble has been recognized for innovative work using data to create tools that support the college choices of our students and then help them persist in college. (See here, here, and here for examples. To play with the “College Bot” tool, make a copy of the document you find at this link.) In this post, I’m going to talk about the tools infrastructure that we use for data-related college work at Noble.
At Noble, we have a small team working on college data:
- Myself: original designer of most of these tools over the past 7 years; deep background in technology from a prior career and ten years of experience on college and counseling related content, but mostly self-taught on our current technologies; majority of time dedicated to non-data and tools related responsibilities
- College Success Software Developer: two plus years working at Noble; career switcher with 2+ years of mostly Python related software development experience prior to coming to Noble; no background in the domain previously
In addition to college data, there is a four person Data Team whose work is largely not involved with college data, instead primarily supporting the academic work at the rest of Noble. This team does most of their work around three pillars that are similar to the practice of other high performing organizations using data to inform instruction, although they are more experienced than most other ed organizations in doing this well–the foundation of this structure has been in place for almost a decade and many other school organizations look to this team for guidance and advice for how to better use data in their system. The three pillars are:
- School Information System (SIS) as the front-end tool for capturing and displaying daily school data (PowerSchool)
- Oracle database as the “back end” for storing the information in the SIS as well as a Postgres data warehouse for any other academic or behavioral data collected from other sources
- Tableau dashboards based on the Oracle and Postgres tables to share the information in timely and digestible ways with teachers, support staff, and leaders across Noble
- Plus a “Fourth pillar”: ad-hoc access and analysis of the above data for requests that aren’t answered by the (many) reports published to Tableau; these are requested via a ticketing system that is also used for custom or unusual issues with the SIS. These analyses and other tasks are based on a range of technologies including R and Python.
Because the college tasks–college counseling and alumni support & tracking–has been largely independent of the main PowerSchool/Tableau work, over the last 7 years we’ve generally acted independently from Noble’s main Data Team.
Our work over the years have been driven by a few main principles that have had consequences for the technology choices and work approach. Some of these principles are in tension–the first two were the original principles and the latter ones were added later to help deal with maintainability and efficiency concerns. At the end of this post, I’ll revisit the consequences of these various principles in a discussion of the challenges they pose going forward.
| Principle | Resulting choices/consequences |
| Innovate quickly and share with users as soon as possible | – Prefer to start with tools like Excel and Google Docs, which can be prototyped in a few hours – Worry less about sustainable processes and more about getting tools to users–manual steps are fine if we can “hack” a solution – We can go from request to resolution for fairly major tools in weeks or less – Most production tools are still in “beta” and have been for years; (the “hacks” can last for years) – “Database” frequently refers to a collection of csv and Excel files in assorted folders |
| Prioritize accessibility and usage by accommodating as many requests as feasible | – A core belief is that many “ed tech” tools have low uptake rates because users switch to worse but more “controllable” options when they experience even a few minutes of frustration (e.g. their own blank Google Sheet) – To combat this, many features are changed from the standard in user-specific or school-specific ways, whenever requested – This approach is a fruitful way to drive continuous improvement because many requests are often merged back to the “standard” settings |
| Minimize technical debt | – As a small team, we’re limited in the number of technologies we can learn and support, particularly if we think about long term maintenance and possible team transitions – As a consequence, we make technology choices like Python that may be sub-optimal for a specific task (e.g. for data analysis vs. R), but which have broader applicability (scripting, website development, etc.) – Another example: instead of writing code in Salesforce’s internal language (Apex), we write Python scripts that interact with Salesforce outside of the system – We try to focus on documentation and test development, but this has been a weakness so far |
| Reduce time spent on repetitive tasks | – As a way to build leverage, time invested in automation can save large amounts of time in the future (although pitfalls exist) – Additionally, time invested in automation can help identify new methods of service to users that were previously not feasible (e.g. automating 12 custom weekly emails makes sending 70 or 200 trivial); as another example, code originally written to grab data from 10 separate Google Docs led the way to doing the same with 4,000 Docs used by alumni – Finally, automation through scripting can serve as part of a solution for documenting knowledge dense or idiosyncratic activities |
| Use industry standard DevOps practices where possible | – As relative novices, we trust in the wisdom of current practice of more experienced developers – In particular, we embrace the ethos for the Free and Open Source (FOSS) software community both out of gratitude and as a way to expand the impact of any innovation – Finally, industry standard techniques simplify human capital development and (eventual) hiring |
As stated above, our team’s work started with the first two principles and added the others over time. In our current work, there is typically an evolution with increasing maturity in phases:
- Prototype in Excel/Google Docs or “spike” in Python analysis using Jupyter Notebooks. Tasks that are performed only a few times a year or annually might remain in this phase indefinitely. Jupyter Notebooks are particularly good for this.
- Create a proper “repository” in Github and manage the creation of command line tools using JIRA. Starting this process can include copying the code from the original Jupyter Notebook “spike.” For many of our most frequently used tools, this could include sending data back and forth with sets of Google Docs and using Python to generate Excel and/or PDF files.
- Migrate the data and then execution of the tool to the cloud. Amazon Web Services (AWS) is our main tool here, although Microsoft Azure offers similar options and we are required to do some work in Google Cloud Platform because of the Google Docs integrations. Further, quick prototypes are sometimes easiest to host on Heroku, which handles networking and security questions in particular with less custom work than does AWS. Getting this right means ongoing operations can take zero to little time during a given week.
- Prototype tools directly to the cloud. This fourth point is added for completeness because some of our tools don’t follow the progression in 2->3 very well because they’re cloud based tools by definition, requiring a public internet location for people to use them. Conceptually, for this subset of tools, steps 2 & 3 are combined and the main technology is either Django or Flask, both Python web frameworks. I won’t be covering these further in the current post.
I’ll end this blog post with some questions about our long term approach, but between here and there will highlight some of the practices in greater detail. Specifically, I’ll cover Jupyter Notebooks (and Python/Pandas), Github and JIRA, and Google Docs integration by way of a new public library.
Jupyter notebooks: This is a tool for running code in a way that lets you do a few interesting things.
- First of all, it works in a browser and can run multiple different programming languages, although we primarily use it with Python.
- Secondly, it’s interactive in a really clever way so that you can run sections of code, look at the output, and then edit what you need to before running it again.
- Third, it lets you write nice comments (in a language called Markdown, which is like simplified HTML) so that you can document what you’re doing for yourself or other teammates. In fact, this makes Jupyter a great choice for automating infrequent tasks–you can save the Notebook you’re working in and come back to it a year later without having to do a ton of extra thinking.
I’ve written a separate blog post about getting started with Python, Pandas (the data tables library in Python) and Jupyter Notebooks. I’d recommend checking that out if you’d like to get started in using those technologies.
If you are more interested in seeing an example of the technology in use for a college project, click here to see a notebook where I work through most of the process to calculate admissions odds for the coming year based on college admissions from the prior year. You can download the actual notebook to run yourself here (although you’ll need to provide your own admissions data.)
Finally, we don’t use this much at Noble yet, but if you’re looking to start out with it, you might want to check out Colab, an extension of Jupyter Notebooks that works inside your (shareable) Google Drive folders. It does some really neat things, including providing code snippets you can paste in, although working with local data is still a little tricky.
Python: here are a few things that Python lets us do:
- Create Excel spreadsheets and PDF files from code, either from scratch or based on raw data files (csv); click here to see the main project we use for creating weekly college counseling reports (go to the tests folder to see the examples)
- Work with data to do sophisticated things like machine learning and other “data science” types of tasks, including analysis and graphing (using Pandas mentioned above and matplotlib for practically any kind of fancy graph)
- Interact with other systems like Salesforce in batch or bulk ways; you can do this with almost any system on the internet, but here’s some very simple code that we use to save the five main tables of our Salesforce database to local csv files and zip them up; instead of saving locally, we also use Python to save to the “cloud storage” service of AWS, S3
- Automatically log into web-based services we use, and download the data files; a good beginner’s resource for this (and many other tasks in Python) is the appropriately named book Automate the Boring Stuff with Python; the author has posted the entire book online for free, but please think about buying it to reward the excellent work
- Create Google Docs and read/write information back and forth between them; if you’re interested in doing this without worrying about the formatting on the Google Docs side too much, I recommend the gspread library; if you’d like to be more precise about formatting, you’ll need to also have code that interacts with Google Apps Script (a version of Javascript that works with Google Cloud tools); to get started with that, you can try using a library I’ve developed for this purpose
- Create websites that are fully interactive and database-driven; we primarily use the python Django framework for this, but Flask works great for smaller projects (and is easier to get started with)
JIRA and Github: several of the examples above are Github repositories, so that illustrates one purpose of Github–sharing code. In addition to that, though, Github and the local tool Git help you keep track of and manage changes for any software project. Git is useful even if you’re only working by yourself–it allows you to “go back in time” to older versions of your code (before you broke it) and also lets you make new changes in a new “branch”, where you can safely mess things up prior to “merging” with the master branch.
Where Git & Github really shine, though, is for collaboration–it has a set of features that let you work with multiple people on the same project and make sure you resolve any conflicts when they occur. We pair this with JIRA, a project management and issue tracking tool to help us manage the entire list of things we’re trying to work on–prioritizing them and help track the intent behind new changes to our code.
To give you a sense of what this looks like, I’m posting a few screenshots from our system to illustrate part of the workflow:
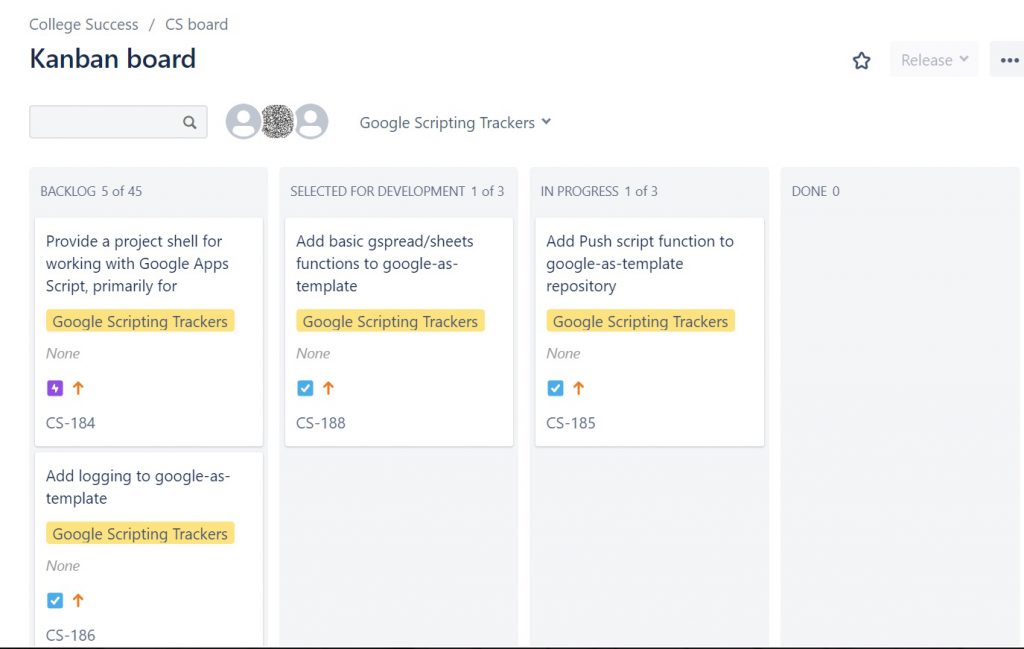
Here is our “Kanban” board in JIRA. I’ve filtered it to just a specific project for working with Google Sheets, but all of our coding “wish list” is here. When we’re ready to work on something or working/done, we move each task to the right 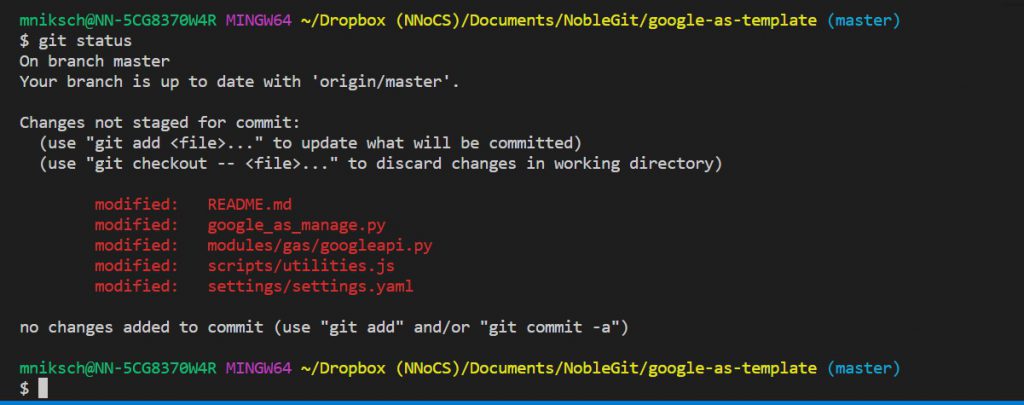
Here, I’ve asked git for the status of a working folder and it responds with all of the files that have changed. I could type ‘git diff ‘ to see the specific changes if I don’t remember. 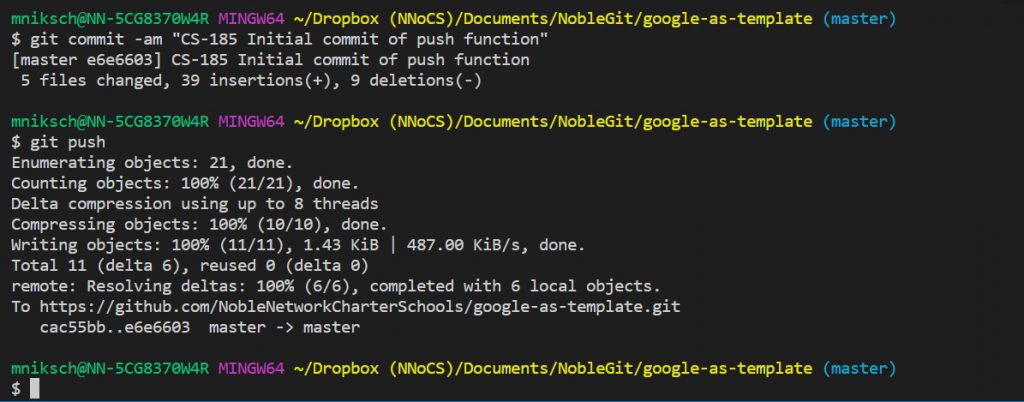
Here, I push the changes from my local machine to Github. Because I use the “CS-185” code at the start of my message, JIRA knows that this change is intended to help with that task 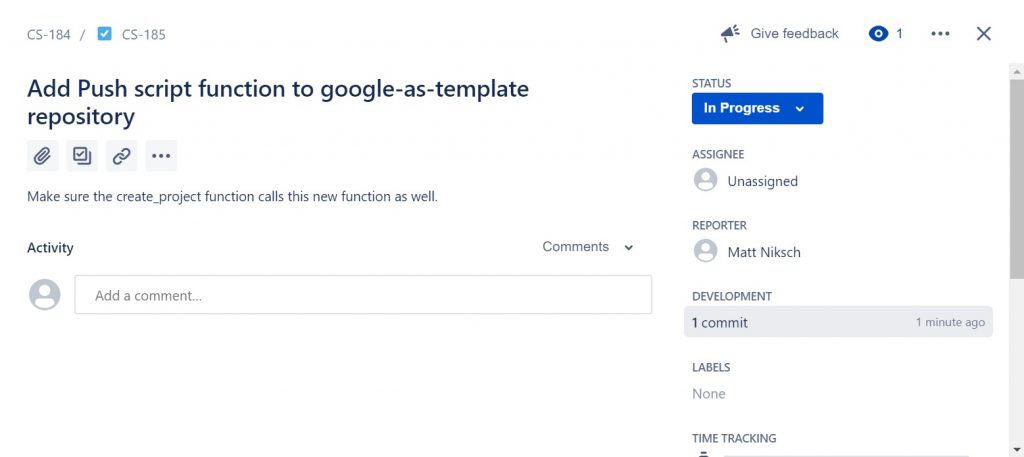
When I click on the task in JIRA, it shows that I just “commited” an associated change 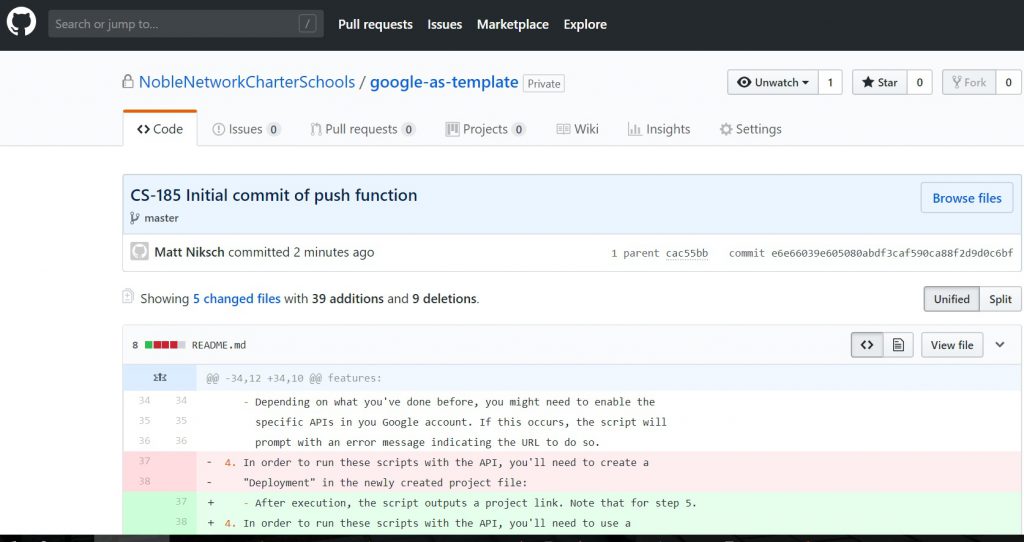
Clicking on the prior link in JIRA will take me to an overview of all of these new changes within Github
That’s all for the specific technologies, although I’m leaving out some of the ways we work with AWS in particular. I’ll finish with a few questions we have been asking ourselves about how we should evolve our practice over the next few years:
- What opportunities exist for us to integrate our work with the 4 Data Team mentioned at the beginning? (Possibly also with 1-2 people from our technology support team who work with infrastructure.) While the work has been mostly silo-ed to date, there’s clearly a case we could make for an expanded capacity via integration. The most obvious analogy is the cross-training that happens with the “DevOps” approach increasingly being adopted by large tech companies. (Our team is probably more Dev than Ops, although we’ve tried to use some of the main DevOps practices where possible. I think the Data Team is probably similar in having a mix, but scale could potentially make both teams better.)
- What other parts of Noble would most benefit from the practices developed here? Their use in the college work is fairly accidental owing to (a) the need to develop new practices as I started creating a new department seven years ago and (b) my unusual background as an engineer who happens to be working in college counseling. Presumably, there are plenty of other functions at Noble where we could improve the lives and daily work of teachers and/or increase the efficacy of student learning or quality of student experience.
- How much of this success is accidental? How critical is it to have a “subject matter expert” also leading a team and writing code? Our first couple of principles in particular would not have been judged prudent by many professional developers, although they approximate a “minimum viable product” approach currently popular in agile development.
- In the funding poor context of public education, how do we do this in a sustainable way? Tech salaries are high enough that a bigger team would quickly draw dollars away from the classroom. Part of our innovation so far has been to squeeze a software development role on top of a salary already carved out for a senior leader. Again, is that an irreproducible accident?
Postscript: this is already a monster post, so I’ll end here, but in case you’re interested, here are a few articles that explore some of these topics further:
- Overview of “Software Development” as a discipline along with brief descriptions of the history, Agile approach, and tips for getting started
- Overview of 10 algorithms used in “Machine Learning” (the second one, logistic regression, is used above)
- Tips for cleaning data with Python/Pandas; some people have said that data cleansing is 80% of the work of data science
- A book length treatment of “DevOps” and the key concepts and consideration; that’s the technical version, you might prefer this novel (!) by the same authors for an easier introduction